I am researching in Uncertainty quantification for Computer Vision and SLAM and am advised by Javier Civera and Ruben Martinez-Cantin under my PhD programme which I started in 2020. Currently, I am visiting the Autonomous System Laboratory (ASL) at ETH Zurich supervised by Cesar Cadena. My trajectory has been driven by my interest in robotics, artificial intelligence, and augmented reality. At my last work station Cologne Intelligence GmbH, Germany, I brought forward the company’s research into visual SLAM systems combined with augmented reality platforms for mobile devices. I completed by Master Thesis on visual localisation systems at TH Köln, Germany. I enriched my university studies by participating with the “Eurobotics Engineering” team in international autonomous robotics competitions.
My Research

LightDepth: Single-View Depth Self-Supervision from Illumination Decline
Javier Rodríguez-Puigvert, Víctor M. Batlle, J.M.M. Montiel, Ruben Martinez-Cantin, Pascal Fua, Juan D. Tardós, Javier Civera
Single-view depth estimation can be remarkably effective if there is enough ground-truth depth data for supervised training. However, there are scenarios, especially in medicine in the case of endoscopies, where such data cannot be obtained. In such cases, multi-view self-supervision and synthetic-to-real transfer serve as alternative approaches, however, with a considerable performance reduction in comparison to supervised case. Instead, we propose a single-view self-supervised method that achieves a performance similar to the supervised case. In some medical devices, such as endoscopes, the camera and light sources are co-located at a small distance from the target surfaces. Thus, we can exploit that, for any given albedo and surface orientation, pixel brightness is inversely proportional to the square of the distance to the surface, providing a strong single-view self-supervisory signal. In our experiments, our self-supervised models deliver accuracies comparable to those of fully supervised ones, while being applicable without depth ground-truth data.
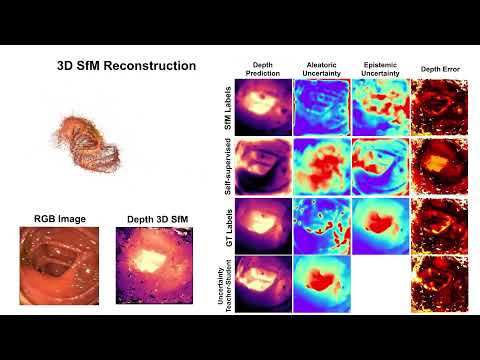
On the Uncertain Single-View Depths in Colonoscopies
Javier Rodríguez-Puigvert,David Recasens, Javier Civera, Rubén Martínez-Cantín
Medical Image Computing and Computer Assisted Intervention 2022
Estimating depth from endoscopic images is a pre-requisite for a wide set of AI-assisted technologies, namely accurate localization, measurement of tumors, or identification of non-inspected areas. As the domain specificity of colonoscopies -- a deformable low-texture environment with fluids, poor lighting conditions and abrupt sensor motions -- pose challenges to multi-view approaches, single-view depth learning stands out as a promising line of for single-view depth estimation in colonoscopies. Their uncertainty quantification offers great potential for such a critical application area. Our specific contribution is two-fold: 1) an exhaustive analysis of Bayesian deep networks for depth estimation in three different datasets, highlighting challenges and conclusions regarding synthetic-to-real domain changes and supervised vs. self-supervised methods; and 2) a novel teacher-student approach
Bayesian Deep Networks for Supervised Single-View Depth Learning
Javier Rodríguez-Puigvert, Rubén Martínez-Cantín, Javier Civera
IEEE Robotics and Automation Letters 2022
Uncertainty quantification is a key aspect in robotic perception, as overconfident or point estimators can lead to collisions and damages to the environment and the robot. In this paper, we evaluate scalable approaches to uncertainty quantification in single-view supervised depth learning, specifically MC dropout and deep ensembles.

Localization Service Using Sparse Visual Information Based on Recent Augmented Reality Platforms
Javier RodríguezPuigvert; Till Krempel; Arnulph Fuhrmann
ISMAR (In Adjunct Proceedings of the IEEE International Symposium for Mixed and Augmented Reality 2018) Munich 2018
We propose a localization service based on sparse visual information using ARCore, a state-of-the-art augmented reality platform for mobile devices. Our service is constituted by two components - front-end and back-end. On the front-end, using the point cloud generated by ARCore as feature points, a corresponding binary keypoint descriptor algorithm like ORB or FREAK is computed to describe the place. On the back-end, this binary descriptor is searched in a map using the bags of binary words technique, responding with the position of the recognized place.

Obstacle Collision Avoidance System for visually impaired based on Tango
Javier Rodríguez Puigvert
Technische Hochschule Köln, 24 Apr 2017
In order to move freely around the space, a user could use this system as a virtual white cane. The Obstacle Collision Avoidance System intends to assist visually impaired people during the obstacle avoidance process using the depth perception of a Tango enable device.
Talks and more
Localization Service Using Sparse Visual Information Based on Recent Augmented Reality Platforms.
8th GeoIT Wherecamp Conference 2018. TU Berlin

Augmented Reality Indoor Navigation with ARCore
MobileTechCon March 2018, Munich, Germany

Tango Step by Step. Indoor Positioning and Navigation
Digility Conference and Expo 2017. Cologne,Germany.

Indoor Navigation with Google Tango
Droidcon UK 2016. London, United Kingdom

Eurobot 2015 Eurobotics Engineering team
Yverdon Les Bains 2015. Switzerland